
티스토리 뷰
- 오라클이 사용하는 메모리의 종류는 크게 두가지로 나눌 수 있다.
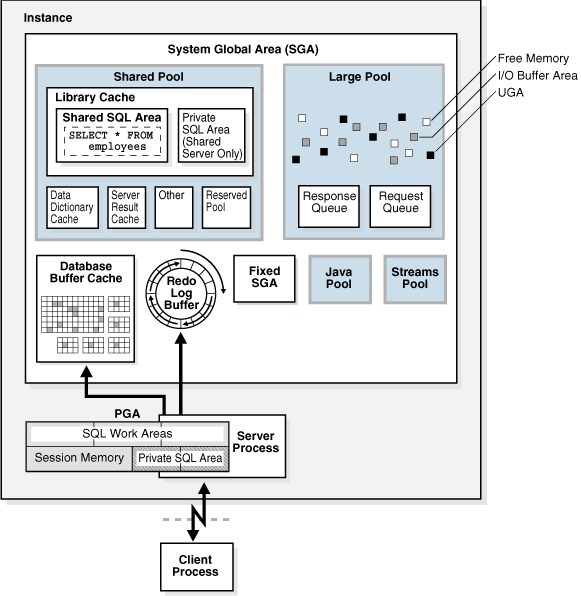
System Global Area(SGA), 그리고 Program Global Area(PGA)가 있다.
SGA는 모든 사용자가 공유 가능한 영역이고, PGA는 공유하는 것이 아니라 사용자마다 개별적으로 사용하는 영역이다. 그래서 Private Area라고도 한다.
- PGA란
PGA는 서버 프로세스에서 생성되며 오라클에서 사용하는 메모리 영역이다.
- 오라클의 두 가지 서버 방식
1) Dedicated 서버 방식; 2) Shared 서버 방식; 두 가지가 존재한다. 각 방식에서 PGA 영역의 역할은 동일하고, UGA 위치만 다르다.
- 오라클 TNS(Transparent Network Substrate)란
모든 표준 네트워크 전송 프로토콜과 함께 작동하는 Oracle Net 기반 계층에 구축된 기반 기술입니다. 오라클에서 사용하는 네트워크 기술이며 Client/Server 또는 Server/Server 간에도 Data의 전송을 가능하게 해주는 기술이다. TNS 기술을 이용하는 SQL*NET 이 사용하는 Listener를 TNS Listener라고 부르며 오라클 서버쪽에 떠 있다.
- 유저 프로세스
- 실제 업무에서는 대부분 Dedicated 서버 방식으로 구성한다. 이 때 유저 프로세스, 서버 프로세스, PGA는 1:1:1로 할당/생성된다.
- Shared Pool:
SQL수행 중 파싱의 역할을 한다. 이 때 파싱은 유저 프로세스에서 요청한 SQL을 수행하기 전 수행할 수 있는 SQL인지 검증/분석하는 단계이다. 파싱에는 다시 소프트 파싱과 하드 파싱, 두 가지가 존재한다. 먼저 소프트 파싱은 검색 단계에서 기존에 동일 SQL이 수행된 것을 확인하고 해당 SQL의 파싱 정보를 재사용한다. 하드 파싱은 기존에 동일한 SQL이 수행되었지만 메모리가 부족하여 LRU 알고리즘에 의해 버려지거나 수행된 적이 없는 SQL로 다시 파싱한다.
(LRU 알고리즘: Least Recently Used (LRU) Page Replacement 알고리즘. 페이지 교체 알고리즘은 페이징 기법으로 메모리를 관리하는 운영체제에서, 페이지 부재가 발생 하여 새로운 페이지를 할당하기 위해 현재 할당된 페이지 중 어느 것과 교체할지를 결정하는 방법이다. )
즉, 이전에 수행된 SQL에 대해 소프트 파싱 유도; 하드 파싱 시 적은 자원 사용;을 통해 파싱을 효과적으로(빠르게) 수행하는 것이 Shared pool의 목적이다.
사용자가 SQL수행 시, 시스템은 공유 풀의 여유공간을 먼저 확인한다. 그리고 나서 free chunk가 있으면 해당 SQL에 대한 파싱 정보를 해시 테이블에 저장할 수 있다. 오라클에선 Free chunk라는 메모리를 관리하는 기법이 바로 LRU 알고리즘(스케줄링)이다. 그 외에도 일반적으로 FIFO, LIFO같은 프로세스 스케줄링 기법이 존재한다.
- Shared pool의 구성요소로, 고정 영역, 동적 영역, Reserved 영역이 있다.
- 각 영역의 개요:
고정 영역: 오라클이 SGA를 관리하는 매커니즘, 파라미터 정보가 저장되어 있다. 크기를 확인하는 방법은 다음과 같다.
SQL> SHOW SGA
Total System Global Area 1207955552 bytes
Fixed Size 9134176 bytes
Variable Size 754974720 bytes
Database Buffers 436207616 bytes
Redo Buffers 7639040 bytes
이 중 Fixed Size가 고정 영역의 크기이다. 파라미터 설정값을 고려하여 시스템이 자동으로 할당하며, 사용자가 직접 지정할 수 없다.
동적 영역: 라이브러리 캐시, 데이터 딕셔너리 캐시로 구성되어 있다. 크기는 SHARED_POOL_SIZE파라미터를 사용하여 지정할 수 있다.
Reserved 영역: 동적 메모리 할당을 위한 공간이다. 주로 파싱 공간을 많이 필요로 하는 SQL파싱에 사용하는 영역이다.
- 동적 영역은 두가지 캐시로 구분된다. 하나는 라이브러리 캐시이고, 나머지 하나는 데이터 딕셔너리 캐시(로우 캐시)이다.
각각의 저장 정보/하는 일:
라이브러리 캐시: 데이터베이스에 접속한 유저가 실행한 SQL, 오라클이 내부적으로 사용하는 SQL(Recursive SQL), SQL에 대한 분석 정보, 실행 계획이 저장된다. 파싱을 수행한다.
데이터 딕셔너리 캐시: 오브젝트 정보(테이블, 인덱스, 함수, 트리거) 및 권한, 시스템 테이블 스페이스의 모든 딕셔너리 정보가 저장되어 있다.
- 라이브러리 캐시의 subpool: Subpool마다 shared pool latch가 존재한다. 그러므로 서버 프로세스는 subpool의 latch에게 메모리 조각(chunk)할당 요청을한다. 이처럼 라이브러리 캐시를 여러 pool로 나누어 shared pool latch에 대해 발생하는 경합을 최소화할 수 있다. Subpool 갯수가 일정 이상이면 ORA-4031 발생할 수 있다.
- 동적 영역의 구성 요소에는 해시 테이블과 LRU 리스트가 있다.
해시 테이블: 현재까지 수행된 모든 SQL을 저장한다. 새로운 SQL 수행 시 해시 테이블을 검색해 기존의 동일 SQL의 존재 유무를 확인한다. 동일한 SQL이 존재하면 소프트 파싱을 한다. 즉, 소프트 파싱 가능 여부를 빠르게 검색하는 것이 주 목적이다.
LRU 리스트: 메모리 공간은 유한하므로, 최근에 가장 적게 사용된 SQL을 메모리에서 삭제, 자주 사용될 SQL정보를 저장/유지한다. 즉, 메모리 사용 효율을 극대화하는 관리 기법이다.
- Shared pool의 저장 요소: 파라미터 정보, 실행된 SQL, SQL 분석/실행 정보, 오라클 오브젝트 정보
- SQL 수행 중 SELECT하는 구문을 예로 들어보면,
1) Syntax(구문) 확인; 2) Semantic 확인; 3) 검색; 4) Optimization; 5) TM 락; 순서로 파싱을 수행한다.
처음의 구문 확인이란, 말 그대로 SQL 구문을 점검해서 문법 오류를 찾아내는 단계이다..
두 번째 시맨틱 확인은, 참조 테이블/컬럼이 실제로 존재하는지 확인한다. 또한, 해당 작업의 권한 여부도 확인한다. 이것은 데이터 딕셔너리 캐시에 캐싱되어 있는 오라클의 데이터 딕셔너리 테이블을 통해 확인한다. 만약 해당 테이블이 존재하지 않으면 해당 정보를 오라클 시스템 테이블 스페이스로부터 데이터 딕셔너리 캐시로 캐싱한다.
세 번째 단계인 검색은 동일 SQL이 수행된 적이 있는지 확인한다. 있다면 해당 SQL의 파싱 정보를 그대로 재사용한다.
- Soft softer parsing: 하나의 세션에서 3번 이상 수행된 SQL에 대해 PGA 영역에 해당 shared cursor 주소값과 SQL 텍스트를 저장한다. 그래서 소프트 파싱할 경우 바로 커서에 액세스한다. 한 편, 세션 종료 시, PGA도 제거되어 커서 정보도 없어진다. WAS 시스템에서 connection pool로 연결된 경우 효과적으로 사용할 수 있다.
- Shared cursor: 실제 수행한 SQL에 대한 정보가 저장되어 있다. 그래서 수행하는 SQL과 동일한 shared cursor가 존재하면 소프트 파싱이 가능하다.
- SESSION_CACHED_CURSOR 파라미터: 하나의 세션에서 캐싱할 수 있는 커서의 수. WAS 시스템에서 connection pool로 연결된 경우 200 이상 설정할 것을 권장한다.
- SQL> SELECT * FROM EMPLOYEES;
SQL> select * from EMPLOYEES;
위 두 SQL은 동일한 문법을 사용하여 동일한 결과를 추출한다. 하지만 대/소문자 불일치로 인해 파싱 결과를 재사용하지 않고 각각 별도로 shared pool에 저장된다. 그러므로 동일 SQL을 다시 실행할 때 정보를 재사용하는 장점을 가지려면 1) 대/소문자 일치; 2) 띄어쓰기 일치; 3) 오브젝트 소유자가 일치;해야 한다. 이렇게 되면 정보를 재사용하여 파싱에 대한 부하를 감소시켜, 전체 런타임 단축, 자원 사용을 감소 시킬 수 있다. 이러한 이유는 파싱에서 검색 단계 중 서버 프로세스가 SQL을 ASCII값으로 전환하여 해시 함수를 수행하기 때문이다.
- Oracle system identifier (SID): 소규모의 경우 한 대의 DB 서버에 한 개의 Instance만 사용하기 때문에 SID와 SERVICE NAME(DB NAME)을 구분할 필요가 없지만 (일반적으로 Single Database일 경우 SID와 SERVICE NAME을 동일하게 운영) 한 대의 DB 서버에서 2개의 Instance(혹은 둘 이상 다중)를 생성하여 orcl1, orcl2를 생성했다면 각각의 Instance는 orcl1, orcl2라는 SID를 갖게 된다. ORACLE_SID 환경 변수는 이 인스턴스를 나중에 생성한 동일 호스트 컴퓨터의 다른 Oracle Database 인스턴스와 구별하는 데 사용된다. 이러한 인스턴스들은 동시에(concurrently) 실행될 수 있다.
- 인스턴스: 하나의 컴퓨터에 위치한 오라클의 프로세스/쓰레드와 공유 메모리 영역을 합한 집합.
.
.
.
.
.
.
.
.
.
.
.
.
'
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
[참고]
https://docs.oracle.com/database/121/CNCPT/memory.htm#CNCPT007
Memory Architecture
During population, the database reads data from disk in its row format, pivots the rows to create columns, and then compresses the data into In-Memory Compression Units (IMCUs). Worker processes (Wnnn) populate the data in the IM column store. Each worker
docs.oracle.com