
티스토리 뷰
[요약] 인덱스 종류:
- B-tree 인덱스는 브랜치 블록과 리프 블록으로 구성되며, 브랜치 블록은 분기를 목적으로 하고 리프 블록은 인덱스를 구성하는 컬럼의 값으로 정렬된다. 일반적으로 OLTP 시스템 환경에서 많이 사용된다.
- Clustered 인덱스는 인덱스의 리프 페이지가 곧 데이터 페이지이며, 리프 페이지의 모든 데이터는 인덱스 키 컬럼 순으로 물리적으로 정렬되어 저장된다.
- Bitmap 인덱스는 시스템에서 사용될 쿼리를 시스템 구현 시에 모두 알 수 없는 Data warehousing, ad-hoc 쿼리 환경을 위해서 설계되었으며, 하나의 인덱스 키 엔트리가 많은 로우(rows)에 대한 포인터를 저장하고 있는 구조이다.
Tuning the Logical Structure
비용 기반 최적화(cost-based optimization)는 쿼리 실행 내에서 nonselective 인덱스의 사용을 방지하는 데 도움이 되지만 SQL 엔진은 사용 여부에 관계없이 테이블에 대해 정의된 모든 인덱스를 계속 유지해야 합니다. 인덱스 유지 관리는 쓰기 집약적인 애플리케이션에서 상당한 CPU 및 I/O 리소스 요구를 나타낼 수 있습니다. 즉, 필요한 경우가 아니면 인덱스를 작성하지 마십시오.
최적의 성능을 유지하려면 애플리케이션에서 사용하지 않는 인덱스를 삭제하십시오. 워크로드를 나타내는 기간 동안 ALTER INDEX MONITORING USAGE 기능을 사용하여 사용되지 않는 인덱스를 찾을 수 있습니다. 이 모니터링 기능은 인덱스 사용 여부를 기록합니다. 인덱스가 사용되지 않은 경우 삭제하십시오. 모니터링할 대표 워크로드를 신중하게 선택하십시오.
Choosing Columns and Expressions to Index
- WHERE 절에서 자주 사용되는 것으로 인덱싱 키를 선택하는 것이 좋습니다.
- selectivity가 높은 인덱스 키. 인덱스의 선택성(selectivity)은 인덱스된 키에 대해 동일한 값을 갖는 테이블의 행 비율입니다. 인덱스의 선택성은 동일한 값을 가진 행이 거의 없는 경우에 최적입니다.
- 낮은 선택도 열을 인덱싱하면 데이터 분포가 왜곡되어 하나 또는 두 개의 값이 다른 값보다 훨씬 덜 자주 발생하는 경우에 도움이 될 수 있습니다.
- 고유한 값이 거의 없는 키 또는 표현식에 표준 B-트리 인덱스를 사용하지 마십시오. 이러한 키 또는 표현식은 일반적으로 선택성이 좋지 않으므로 자주 선택하는 키 값이 다른 키 값보다 덜 자주 나타나지 않는 한 성능을 최적화하지 않습니다. 인덱스가 자주 수정되는 높은 동시성 OLTP 응용 프로그램이 포함되지 않는 한 이러한 경우 비트맵 인덱스를 효과적으로 사용할 수 있습니다.
- 자주 수정되는 열은 인덱싱하지 마십시오. 인덱싱된 열을 수정하는 UPDATE 문과 인덱싱 된 테이블을 수정하는 INSERT 및 DELETE 문은 인덱스가 없는 경우보다 시간이 더 오래 걸립니다. 이러한 SQL 문은 인덱스의 데이터와 테이블의 데이터를 수정해야 합니다. 또한 추가 실행 취소 및 다시 실행을 생성합니다.
- 함수나 연산자가 있는 WHERE 절에만 나타나는 키를 인덱싱 하지 마십시오. MIN 또는 MAX 이외의 함수를 사용하는 WHERE 절 또는 인덱스 키가 있는 연산자는 함수 기반 인덱스를 제외하고 인덱스를 사용하는 액세스 경로를 사용 가능하게 만들지 않습니다.
- 많은 수의 동시 INSERT, UPDATE 및 DELETE 문이 상위 및 하위 테이블에 액세스 하는 경우 참조 무결성 제약 조건의 외래 키 인덱싱을 고려하십시오. 이러한 인덱스는 자식 테이블을 공유 잠금하지 않고 부모 테이블에서 UPDATE 및 DELETE를 허용합니다.
Using Bitmap Indexes
비트맵 인덱스는 다음 특성을 모두 포함하는 쿼리의 성능을 크게 향상시킬 수 있습니다.
비트맵 인덱스는 GENDER, MARITAL_STATUS 및 RELATION과 같이 고유한 값이 낮은 열에 가장 적합하다는 것이 일반적인 통념입니다. 그러나 이 가정은 완전히 정확하지 않습니다. 실제로 많은 동시 시스템(concurrent systems)에서 데이터가 자주 업데이트되지 않는 시스템에는 비트맵 인덱스가 항상 권장됩니다. 실제로 여기에서 설명할 것처럼 100% 고유 값(기본 키에 대한 열 후보)이 있는 열의 비트맵 인덱스는 B-트리 인덱스만큼 효율적입니다.
- WHERE 절에 카디널리티가 낮거나 중간인 열에 대한 여러 조건자(predicates)가 포함된 경우.
- 카디널리티(cardinality) - SQL에서 카디널리티라는 용어는 데이터베이스 테이블의 특정 열에 포함 된 데이터 값의 고유성을 나타냅니다. 카디널리티가 낮을수록 열에서 더 많은 요소가 중복됩니다. 따라서 가능한 가장 낮은 카디널리티를 가진 열은 모든 행에 대해 동일한 값을 갖습니다.
- 이러한 낮은 또는 중간 카디널리티 열의 개별 조건자는 많은 수의 행을 선택하는 경우.
- 비트맵 인덱스는 이러한 낮은 또는 중간 카디널리티 열의 일부 또는 전체에 만들어진 경우.
- 쿼리 중인 테이블에 많은 행이 있는 경우.
여러 비트맵 인덱스를 사용하여 단일 테이블의 조건을 평가할 수 있습니다. 따라서 비트맵 인덱스는 긴 WHERE 절이 포함된 복잡한 임시 쿼리에 매우 유리합니다. 비트맵 인덱스는 또한 집계 쿼리와 스타 스키마의 조인 최적화를 위한 최적의 성능을 제공할 수 있습니다.
Comparing B-tree Indexes to Bitmap Indexes
비트맵 인덱스는 B-트리 인덱스를 사용하는 것보다 스토리지를 상당히 절약할 수 있습니다.
이 B-트리 인덱스는 많은 양의 공간을 필요로 할 뿐만 아니라 정렬됩니다. 데이터베이스를 완전히 인덱싱하려면 이러한 열의 다른 순열(permutations)에 대한 인덱스를 생성해야 합니다. 3개의 낮은 카디널리티 열의 간단한 경우에는 6개의 가능한 복합 B-트리 인덱스가 있습니다. 생성할 복합 B-트리 인덱스를 결정할 때 디스크 공간과 성능 요구 간의 균형을 고려해야 합니다.
비트맵 인덱스는 이 딜레마를 해결합니다. 비트맵 인덱스는 쿼리 실행 중에 효율적으로 결합될 수 있으므로 3개의 작은 단일 열 비트맵 인덱스가 6개의 3열 B-트리 인덱스의 작업을 수행할 수 있습니다.
비트맵 인덱스는 특히 데이터 웨어하우징 환경에서 B-트리 인덱스보다 훨씬 더 효율적입니다. 비트맵 인덱스는 효율적인 공간 활용뿐만 아니라 효율적인 실행을 위해 생성되는데 후자가 좀 더 중요합니다.
고유 키 열(unique key columns)에 비트맵 인덱스를 만들지 마십시오. 그러나 각 값이 수백 또는 수천 번 반복되는 열의 경우 비트맵 인덱스는 일반적으로 일반 B-트리 인덱스 크기의 25% 미만입니다. 비트맵 자체는 압축된 형식으로 저장됩니다.
그러나 단순히 B-트리와 비트맵 인덱스의 상대적 크기를 비교하는 것만으로는 효율성을 정확하게 측정할 수 없습니다. 성능 특성이 다르기 때문에 카디널리티가 높은 열에는 B-트리 인덱스를 유지하고 카디널리티가 낮은 열에는 비트맵 인덱스를 만듭니다.
잠금 문제(locking issues)는 DML 작업에 영향을 미치며 과도한 OLTP 환경에 영향을 줄 수 있습니다. 그러나 잠금 문제는 쿼리 성능에 영향을 미치지 않습니다. 다른 유형의 인덱스와 마찬가지로 비트맵 인덱스 업데이트는 비용이 많이 드는 작업입니다. 그럼에도 불구하고 단일 명령문에서 많은 행이 삽입되거나 많은 업데이트가 수행되는 대량 삽입 및 업데이트의 경우 비트맵 인덱스가 일반 B-트리 인덱스보다 성능이 더 좋을 수 있습니다.
Using Clusters
클러스터는 공통 열(common columns)을 공유하고 일반적으로 함께 사용되기 때문에 물리적으로 함께 저장되는 하나 이상의 테이블 그룹입니다. 관련된 행이 물리적으로 함께 저장되기 때문에 디스크 액세스 시간이 향상됩니다.
클러스터를 생성하려면 CREATE CLUSTER 문을 사용합니다.
테이블을 클러스터링할지 여부를 결정할 때 다음 지침을 따르십시오.
- 애플리케이션이 테이블을 가끔씩만 조인하거나 공통 열 값을 자주 수정하는 경우 테이블을 클러스터링하지 마십시오. Oracle이 클러스터를 유지 관리하기 위해 수정된 행을 다른 블록으로 마이그레이션해야 할 수도 있기 때문에 행의 클러스터 키 값을 수정하는 것은 클러스터 되지 않은 테이블의 값을 수정하는 것보다 더 오래 걸립니다.
아래 그림과 같이 인덱스가 없는 구조에서는 데이터 페이지에 데이터들이 입력된 순서대로 기록됩니다.
(구조를 쉽게 이해하기 위해서 페이지당 데이터가 3개씩 들어간다고 가정합니다.)

인덱스가 없는 데이터 구조
클러스터 인덱스 구조
클러스터 인덱스 구조에서 인덱스 페이지의 루트 노드 및 중간 노드들은 인덱스 행을 포함하게 구성되어 있습니다.
리프 노드들은 기본 테이블의 데이터 페이지로 구성되어 있습니다.
기본 테이블 데이터 페이지의 데이터 값들은 인덱스 값을 기준으로 정렬되어 있습니다.
인덱스 페이지를 통해서 인덱스를 검색하여 해당하는 데이터 페이지를 찾아가도록 구성되어 있습니다.

msdn의 클러스터 인덱스 구조
예제를 통한 클러스터 인덱스 설명
클러스터 인덱스 생성시
위에서 테스트로 생성한 TestTbl 테이블의 "UserInitial" 컬럼에 클러스터 인덱스를 구성하게 되면
내부구조는 어떻게 변할까요?
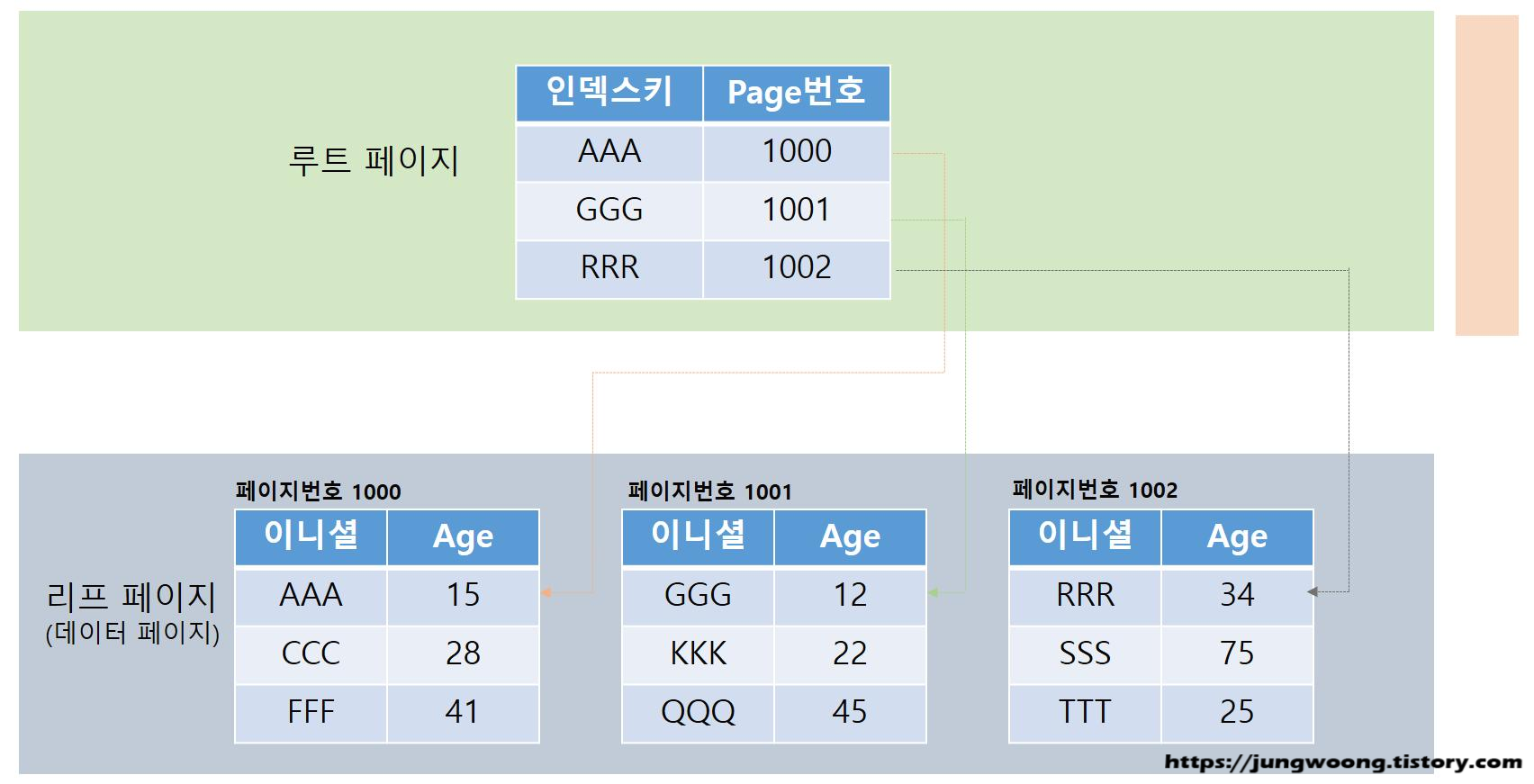
클러스터 인덱스 구조
위와 같이 인덱스 페이지 가 생성되게 됩니다.
클러스터 인덱스 페이지의 루트 페이지에는 B-Tree로 정렬된 리프 페이지의 첫 번째 "UserInitial" 컬럼의 값과
페이지 번호로 맵핑됩니다.
클러스터 인덱스 페이지의 리프 페이지에는 데이터 페이지로 구성되어 있습니다.
데이터 페이지의 데이터들은 "UserInitial"열을 기준으로 정렬됩니다.
클러스터 인덱스 검색
TestTbl 테이블에서 FFF 값을 검색한다면 아래와 같이 수행될 것입니다.
SELECT * FROM TestTbl WHERE UserInitial = 'FFF'
클러스터 인덱스 검색
첫 번째로 인덱스의 루트 페이지를 접근해서 찾는 값이 어떤 리프 페이지(데이터 페이지)에 있는지 확인 후
리프 페이지로 이동 후에 페이지의 내부 행들을 검색해서 해당 데이터를 찾는 순서로 구성됩니다.
검색 과정에서 총 2개의 페이지(루트 페이지 + 리프 페이지)를 참조합니다.
클러스터 인덱스 범위 검색
TestTbl 테이블에서 FFF에서 QQQ사이의 범위 검색한다면 DB내부에서는 아래와 같이 동작할 것입니다.
SELECT * FROM TestTbl WHERE UserInitial >= 'FFF' AND UserInitial <= 'QQQ'
FFF의 페이지를 찾은 다음에 데이터가 정렬되어 있기 때문에 순차적으로 QQQ가 나올 때까지 읽으면
검색 데이터를 모두 찾을 수 있습니다. (비 클러스터 인덱스의 경우 정렬되어 있지 않기 때문에 비효율적 아래 설명)
클러스터 인덱스 삽입
HHH라는 데이터를 Insert 하게 되면 어떻게 동작할까요?

데이터 삽입1

데이터 삽입2
데이터 검색과 같이 인덱스를 통해서 삽입 위치를 찾습니다. 만약에 해당 페이지에 공간이 있다면 인덱스 순서에
맞도록 데이터가 넣어집니다. 하지만 페이지가 가득 차게 될 경우 위의 그림과 같이 페이지 분할 작업이 발생됩니다.
참고:
https://docs.oracle.com/cd/B10501_01/server.920/a96533/data_acc.htm#8131
Understanding Indexes and Clusters
This chapter provides an overview of data access methods using indexes and clusters that can enhance or degrade performance. The chapter contains the following sections: Understanding Indexes This section describes the following: Tuning the Logical Structu
docs.oracle.com
https://www.oracle.com/technical-resources/articles/sharma-indexes.html
https://jungwoong.tistory.com/34
[MSSQL] 인덱스의 내부 동작 방식
SQL Server 의 내부 데이터 관리 방식 내용의 이해를 위해서는 SQL Server의 데이터 관리방식의 글을 읽어 보시고 오시면 이해를 하시는데 도움이 됩니다. 링크 SQL Server의 데이터 관리 데이터베이스
jungwoong.tistory.com